Resurrect path_to_inst file
To rescue /etc/path_to_inst file you have two options:
echo "#path_to_inst_bootstrap_1" > /etc/path_to_inst; reboot -- -r
or
reboot -- -a
Opening keynote of Oracle OpenWorld 2009
I suggest everyone to follow this link to plunge into atmosphere of Oracle’s keynote event kindly presented by Ben Rockwood. Besides that, you’ll receive quite a few of information about Oracle’s take on Sun’s acquisition.
Solaris 10 10/09 hit the road
Without any hype a new Solaris 10 release has seen the light with bunch of glowing features, i.e. caching devices support in ZFS, ZFS user/group quotas, zone parallel patching, callout subsystem enhancements, etc. Please, visit the original “What’s new” document at docs.sun.com for more details.
Update. Just have came across a useful link that could help you to find a way in Solaris release names
Backup and restore Sun Cluster
Imagine for a second, even if it’s extremely unusual situation, that both nodes of your cluster have miserably failed simultaneously because of a buggy component. And now there is a dilemma what to do next: whether to reconfigure everything from scratch or, since you’re a vigilant SA, use the backups. But how to restore cluster configuration, did devices, resource and disk groups, etc? I tried to simulate such a failure in my testbed environment using the most simple SC configuration with one node and two VxVM disk groups to give a general overview and to show how easy and straightforward the whole process is.
As you might already know CCR (Cluster Configuration Repository) is a central database that contains:
- Cluster and node names
- Cluster transport configuration
- The names of Solaris Volume Manager disk sets or VERITAS disk groups
- A list of nodes that can master each disk group
- Operational parameter values for data services
- Paths to data service callback methods
- DID device configuration
- Current cluster status
This information is kept under /etc/cluster/ccr so it’s quite obvious that we need a whole backup of /etc/cluster directory since some crucial data, i.e. nodeid, are stored under /etc/cluster as well:
# cd /etc/cluster; find ./ | cpio -co > /cluster.cpio
And don’t forget about /etc/vfstab, /etc/hosts, /etc/nsswitch.conf and /etc/inet/ntp.cluster files. Of course, there are a lot more to keep in mind, but here I’m speaking only about SC related files. Now, here goes the trickiest part. What would I give it such a strong name? Because I learned this hard way during my experiment and if you omit it you won’t be able to load did module and recreate DID device entries (here I deliberately decided not to backup /devices and /dev directories). Wright down or try to remember the output:
# grep did /etc/name_to_major
did 300# grep did /etc/minor_perm
did:*,tp 0666 root sys
Of course, you could simply add those two files to the backup list – whatever you prefer.
Now it’s safe to reinstall OS and once it’s done install SC software. Don’t run scinstall – it’s unnecessary.
First, create a new partition for globaldevices on the root disk. It’s better to assign it the same number as it was before the crash to avoid editing /etc/vfstab file and bothering with scdidadm command. Next, edit /etc/name_to_major and /etc/minor_perm files and make appropriate changes or simply overwrite them with copies form your backup. Now do a reconfiguration reboot:
# reboot — -r
or#halt
ok> boot -ror
# touch /reconfigure; init 6
When you’re back check that did module was loaded and there is pseudo/did@0:admin under /devices path:
# modinfo | grep did
285 786f2000 3996 300 1 did (Disk ID Driver 1.15 Aug 20 2006)# ls -l /devices/pseudo/did\@0\:admin
crw——- 1 root sys 300, 0 Oct 2 16:30 /devices/pseudo/did@0:admin
You should also see that /global/.devices/node@1 was successfully mounted. So far, so good. But we are still in a non cluster mode. Lets fix that.
# mv /etc/cluster /etc/cluster.orig
# mkdir /etc/cluster; cd /etc/cluster
# cpio -i < /cluster.cpio
Restore other files, i.e. /etc/vfstab and others of that ilk, and reboot your system. Once it’s back again double check that DID entries have been created:
# scdidadm -l
1 chuk:/dev/rdsk/c1t6d0 /dev/did/rdsk/d1
2 chuk:/dev/rdsk/c2t0d0 /dev/did/rdsk/d2
3 chuk:/dev/rdsk/c2t1d0 /dev/did/rdsk/d3
4 chuk:/dev/rdsk/c3t0d0 /dev/did/rdsk/d4
5 chuk:/dev/rdsk/c3t1d0 /dev/did/rdsk/d5
6 chuk:/dev/rdsk/c6t1d0 /dev/did/rdsk/d6
7 chuk:/dev/rdsk/c6t0d0 /dev/did/rdsk/d7
# for p in `scdidadm -l | awk '{print $3"*"}' `; do ls -l $p; done
Finally, import VxVM disk group, if that’s haven’t been done automatically and bring them online:
# vxdg import testdg
# vxdg import oradg
# scstat -D
-- Device Group Servers --
Device Group Primary Secondary
------------ ------- ---------
Device group servers: testdg testbed -
Device group servers: oradg testbed -
-- Device Group Status --
Device Group Status
------------ ------
Device group status: testdg Offline
Device group status: oradg Offline
# scswitch -z -D oradg -h testbed
# scswitch -z -D testdg -h tetbed
# scstat -D
-- Device Group Servers --
Device Group Primary Secondary
------------ ------- ---------
Device group servers: testdg testbed -
Device group servers: oradg testbed -
-- Device Group Status --
Device Group Status
------------ ------
Device group status: testdg Online
Device group status: oradg Online
Easy!
In: Solaris · Tagged with: sun cluster
Another video from Australia Kernel Conference
A hilarious video that elates your for the rest of the day even if you’re not from Down Under “How to survive as an Aussie Kernel Engineer”
Cheers!
Snow Leopard and madwimax
If you’re one of the Yota’s frustrated users, me is also included, because of lack support for Snow Leopard, then here is a possible solution, though being currently under development, that could possibly make you a bit happier and fill your soul with hope:
- Download http://tuntaposx.sourceforge.net/download.xhtml.
- Download and unzip http://wart.highsecure.ru/madwimax.zip.
- Uninstall Yota access software/drivers.
- Plug the modem.
- Run Terminal.app and cd into directory where you unpacked zip archive.
- Run sudo ./start_madwimax.sh
- Enjoy!
Note, that this solution is under development and there is no guarantee it will work for you but still it’s the only option we all have at the moment. As far as I know, the patches have been already sent to the upstream project (madwimax) so it’s expected to become more matured in the near future. For now, lets say “Thank you” to the guys who’ve made it possible: siglost, kesik and of course the initial author of madwimax Alexander Gordeev.
In: Apple · Tagged with: mac os x, yota
Keynote speech from Jeff Bonwick and Bill Moore
If you followed Kernel Conference Australia 2009, also mentioned in my blog here, you’d noticed that not every presentation was available for online visitors and that made me mirthless, since I was so much keen on listening about ZFS and its future, i.e. quota support, dedup, triple raidz, shadow migration, etc. from the creator’s lips. But no more brooding, for today this video was finally published at Sun’s Video Blog. Enjoy!
In: Solaris · Tagged with: zfs
Oracle’s Exadata innuendo
During todays conference organized by Brocade and called “Brocade Extraordinary Networks 2009”, I couldn’t leave unnoticed a presentation made by Sun Microsystem’s Senior Systems Architect in CIS region Vitaly Soloviev about recently announced Exadata V2. Though I learnt nothing new, there was one thing that drew my attention so now I couldn’t get it out of my head – answering a question from the audience “if it’s doable to use another Exadata rack on the remote site and make the two highly available to tolerate the failures and does such built-in feature ever exist” Vitaly replied he wasn’t eligible to answer such questions and we just should be patient. Lets wait and see, what else Oracle keeps under its sleeve…
Two sessions from Java ComunityOne 2009
If you haven’t attended CommunityOne conference then here is a sweat gift from Sun Video blog materialised in “Becoming a ZFS ninja” and “Developing in OpenSolaris: Solaris Device Drivers” presentations driven by Ben Rockwood and Max Bruning respectively. Enjoy.
In: Solaris · Tagged with: zfs
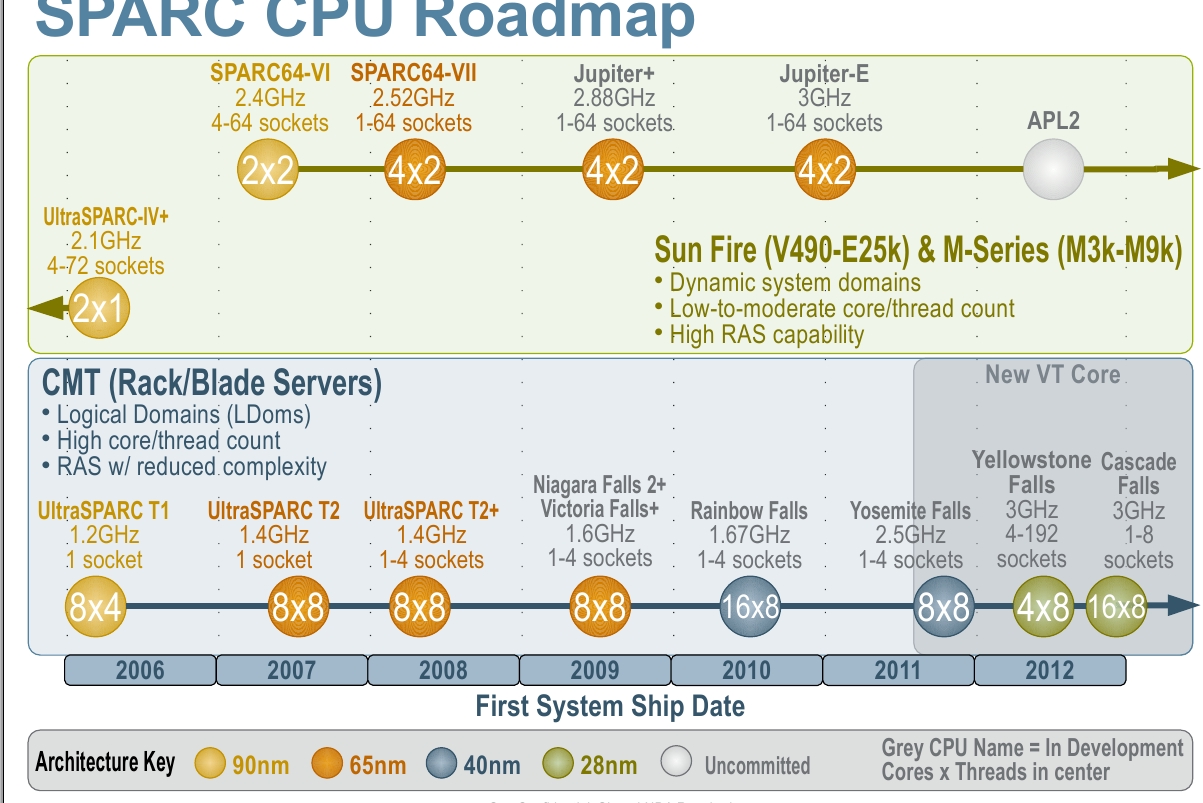
Sun’s SPARC CPU Roadmap
Saw it a couple of days ago but recently this “confidential” information has leaked into public. Now it’s clear that so much anticipated and hyped Rock CPU is out of the game.
{kind=link}