No video during the flight
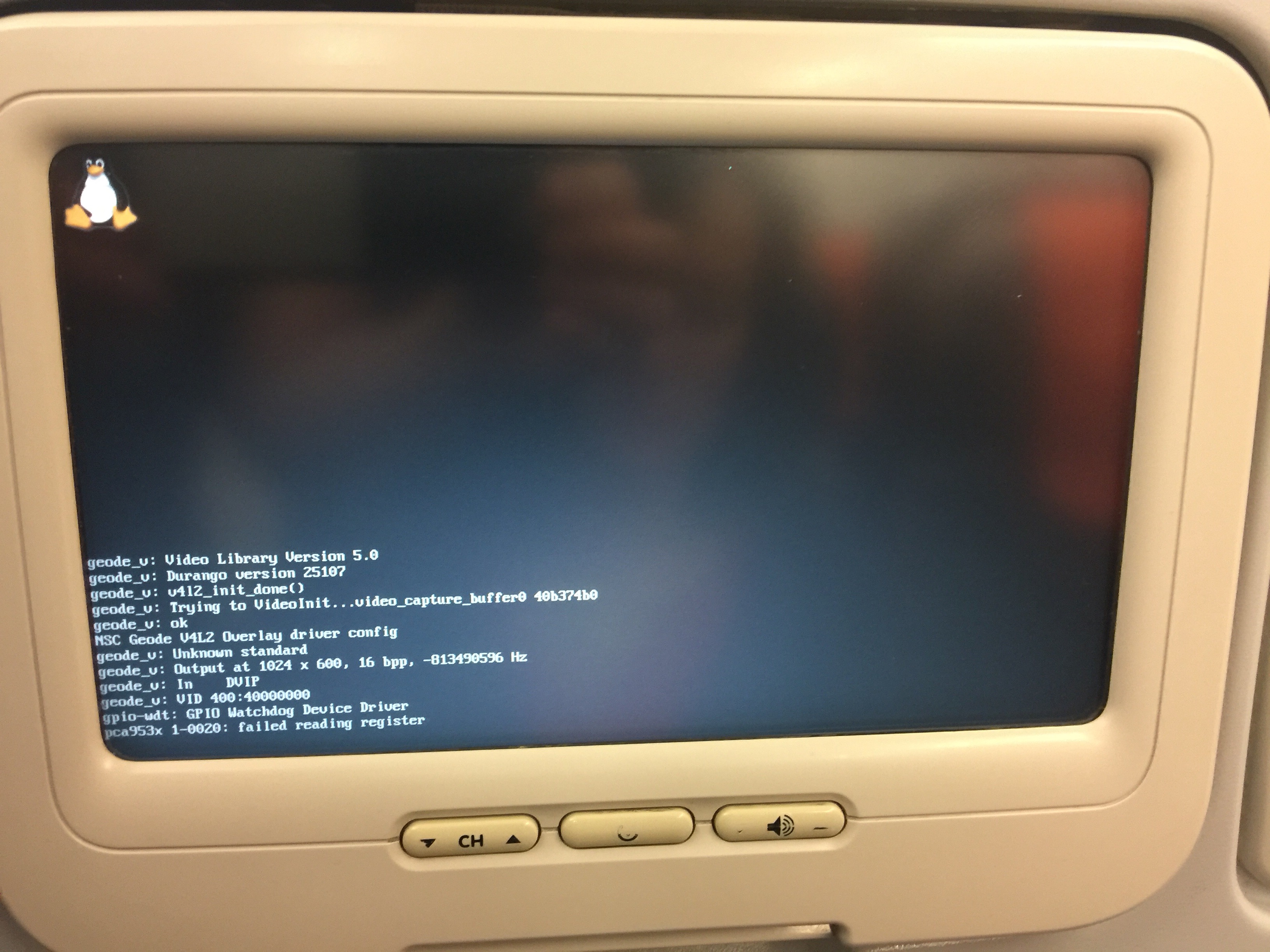
Don’t know what version of Linux they were running but looks like one of the following code paths triggered the issue:
static int pca953x_read_regs(struct pca953x_chip *chip, int reg, u8 *val)
{
int ret;
ret = chip->read_regs(chip, reg, val);
if (ret < 0) { dev_err(&chip->client->dev, "failed reading register\n");
return ret;
}
return 0;
}
static int pca953x_read_single(struct pca953x_chip *chip, int reg, u32 *val, int off)
{
int ret;
int bank_shift = fls((chip->gpio_chip.ngpio - 1) / BANK_SZ);
int offset = off / BANK_SZ;
ret = i2c_smbus_read_byte_data(chip->client,
(reg << bank_shift) + offset);
*val = ret;
if (ret < 0) { dev_err(&chip->client->dev, "failed reading register\n");
return ret;
}
return 0;
}
Things to keep in mind about HTTP/2
This talk is just unbelievably helpful.
MongoDB 3.4 or stay on 3.2?
If you’re herding multiple shards this one should be convincing enough to jump on 3.4 bandwagon:
mongos> sh.getBalancerHost() getBalancerHost is deprecated starting version 3.4. The balancer is running on the config server primary host.
Moving to OmniOS Community Edition
Had a small snag when I tried to upgrade my old (r151018) OmniOS installation to OmniOS CE as described in the ANNOUNCEMENT OmniOS Community Edition – OmniOSce r151022h
During “pkg update” stage I got something similar to the following:
pkg update: The certificate which issued this certificate:/C=US/ST=Maryland/O=OmniTI/OU=OmniOS/CN=OmniOS r151018 Release
Signing Certificate/emailAddress=omnios-supp…@omniti.com could not be found.
Thankfully, the solution was a straightforward sequence of steps to upgrade to r151020, then to r151021 and finally to r151022.
From there I was able to successfully upgrade to OmniOS CE. Even “-r” option in “pkg update -rv” worked as a charm because this option doesn’t exist in r151018. Probably, I could skip r151021 all together, but it’s always better be safe than sorry.
How to reuse dropped sharded collection’s name
It happens that sometimes you want to drop your sharded collection and be able to reuse its name again. However, it might not be as straightforward as one expects it to be:
mongos>sh.shardColelction("your_database.your_collection", { "sharded_key": 1})
"code" : 13449,
"ok" : 0,
"errmsg" : "exception: collection your_database.your_collection already sharded"
The error message might be different but you get the idea – you can’t shared a collection if its name matches the one that has been recently dropped. Thankfully, there is a workaround described in SERVER-17397:
When dropping a collection:
use config
db.collections.remove( { _id: "DATABASE.COLLECTION" } )
db.chunks.remove( { ns: "DATABASE.COLLECTION" } )
db.locks.remove( { _id: "DATABASE.COLLECTION" } )
Connect to each mongos and run flushRouterConfig
Followed the steps in prod yesterday and it worked like a charm.
TIL MongoDB Index Build could exceed 100%
A quote from SERVER-7631:
Since data can be inserted while its running, this can go over 100 by design.
TIL Remove a Znode from Zookeeper
Yep, you could easily achieve that (and much more) using zkCli.sh (Zookeeper client):
$ /usr/share/zookeeper/bin/zkCli.sh Connecting to localhost:2181 Welcome to ZooKeeper! JLine support is enabled WATCHER:: WatchedEvent state:SyncConnected type:None path:null [zk: localhost:2181(CONNECTED) 0] help ZooKeeper -server host:port cmd args connect host:port get path [watch] ls path [watch] set path data [version] rmr path delquota [-n|-b] path quit printwatches on|off create [-s] [-e] path data acl stat path [watch] close ls2 path [watch] history listquota path setAcl path acl getAcl path sync path redo cmdno addauth scheme auth delete path [version] setquota -n|-b val path
Issue “rmr” (to remove recursively) or “delete” to remove a znode.
TIL HSTS requires a secure transport
Otherwise (quoting RFC6797):
If an HTTP response is received over insecure transport, the UA MUST ignore any present STS header field(s).
That means SSL certificate on your server must be valid, i.e. no errors or warnings when you open a page from a browser over https.
Restart your Mongos after maxConsecutiveFailedChecks
Take it literally.
If you configured your MongoDB config servers as a replica set and for some reason, say a network outage, Mongos server lost connection to all of them and is not able to reconnect during maxConsecutiveFailedChecks attempts then, surprise, it becomes useless. Even if the network is up and running again, Mongos will not reconnect to the config servers and you won’t be able to authenticate to your shard cluster until Mongos is restarted.
From https://api.mongodb.com/cplusplus/current/classmongo_1_1_replica_set_monitor.html
static int maxConsecutiveFailedChecks = 30 If a ReplicaSetMonitor has been refreshed more than this many times in a row without finding any live nodes claiming to be in the set, the ReplicaSetMonitorWatcher will stop periodic background refreshes of this set.
And if you check the source code of 3.2.x (3.2.12 as of this writing) branch you will see the following (./src/mongo/client/replica_set_monitor.cpp):
if (_scan->foundAnyUpNodes) {
_set->consecutiveFailedScans = 0;
} else {
_set->consecutiveFailedScans++;
if (timeOutMonitoringReplicaSets) {
warning() << "All nodes for set " << _set->name << " are down. "
<< "This has happened for " << _set->consecutiveFailedScans
<< " checks in a row. Polling will stop after "
<< maxConsecutiveFailedChecks - _set->consecutiveFailedScans
<< " more failed checks";
}
}
So once you go pass maxConsecutiveFailedChecks the replica set will become unusable:
bool SetState::isUsable() const {
return consecutiveFailedScans < maxConsecutiveFailedChecks;
}
As far as I can't tell 3.4.x doesn't have maxConsecutiveFailedChecks and hopefully one will not have to intervene and restart Mongos manually.
Watch “Monitorama 2016: All of Your Networking Monitoring is (probably) wrong” talk
Just came across this talk being mentioned in the comments on Hacker news and, boy, it’s absolutely amazing!
Watch this hilarious talk here – Monitorama 2016: All of Your Networking Monitoring is (probably) wrong
Btw, the talk is presented, presumably, by the same guy who wrote Monitoring and Tuning the Linux Networking Stack: Receiving Data and Monitoring and Tuning the Linux Networking Stack: Sending Data which are both must-read.